
The global AI landscape is experiencing a calibrated shift toward structural efficiency. Sina Weibo researchers recently introduced VibeThinker-3B, a tiny AI model that matches or exceeds the reasoning capabilities of massive systems from Google DeepMind and OpenAI. While industry giants rely on hundreds of billions of parameters, this compact system proves that precision post-training can yield superior results on critical benchmarks like AIME 2026 and LiveCodeBench.
Breaking the Scale Monopoly: Benchmark Results
VibeThinker-3B achieved a remarkable score of 94.3 on AIME 2026. This performance baseline matches DeepSeek V3.2, despite that model possessing 224 times more parameters. Furthermore, the tiny AI model outperformed Gemini 3 Pro, which scored 91.7. Consequently, the researchers demonstrated that smaller, optimized models can dominate in verifiable reasoning tasks such as mathematics and logic.
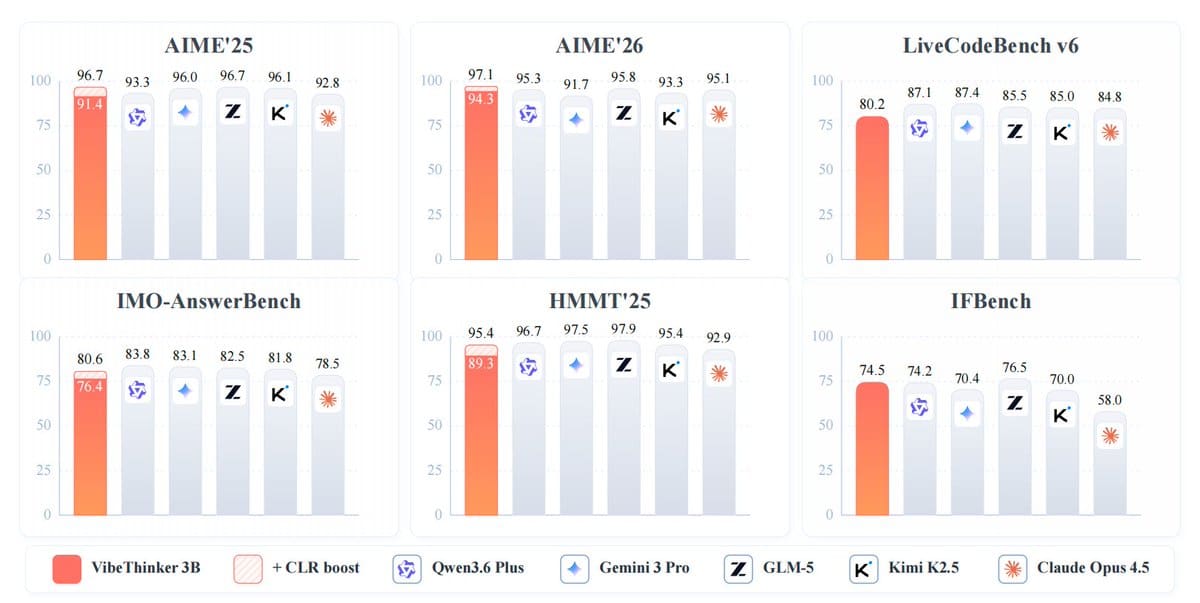
In coding evaluations, the results were equally disruptive. The model secured an 80.2 Pass@1 score on LiveCodeBench v6. It also maintained a 96.1% acceptance rate on unseen LeetCode contests. Specifically, it passed 123 out of 128 first-attempt submissions, surpassing the performance of GPT-5.2 and Claude Opus 4.6 under identical testing conditions.
The Situation Room: The Translation
To understand this development, we must analyze the Parametric Compression-Coverage Hypothesis. The researchers argue that reasoning—unlike broad factual knowledge—can be compressed into smaller architectures without losing precision. By focusing on “reasoning traces” and removing redundant data, they created a catalyst for high-performance computing on limited hardware. Essentially, they traded “encyclopedic memory” for “logical depth.”
Strategic Training and Knowledge Limits
The development of this tiny AI model involved a sophisticated four-stage post-training process. The team utilized Alibaba’s Qwen2.5-Coder-3B as a baseline, applying MaxEnt-Guided Policy Optimization. Notably, they opted for a static 64,000-token window. They discovered that progressive window expansion actually reduced performance at the 3B scale. However, the model does have limitations. It scored lower on GPQA-Diamond, a test for broad scientific knowledge, where Gemini 3 Pro remains the leader.
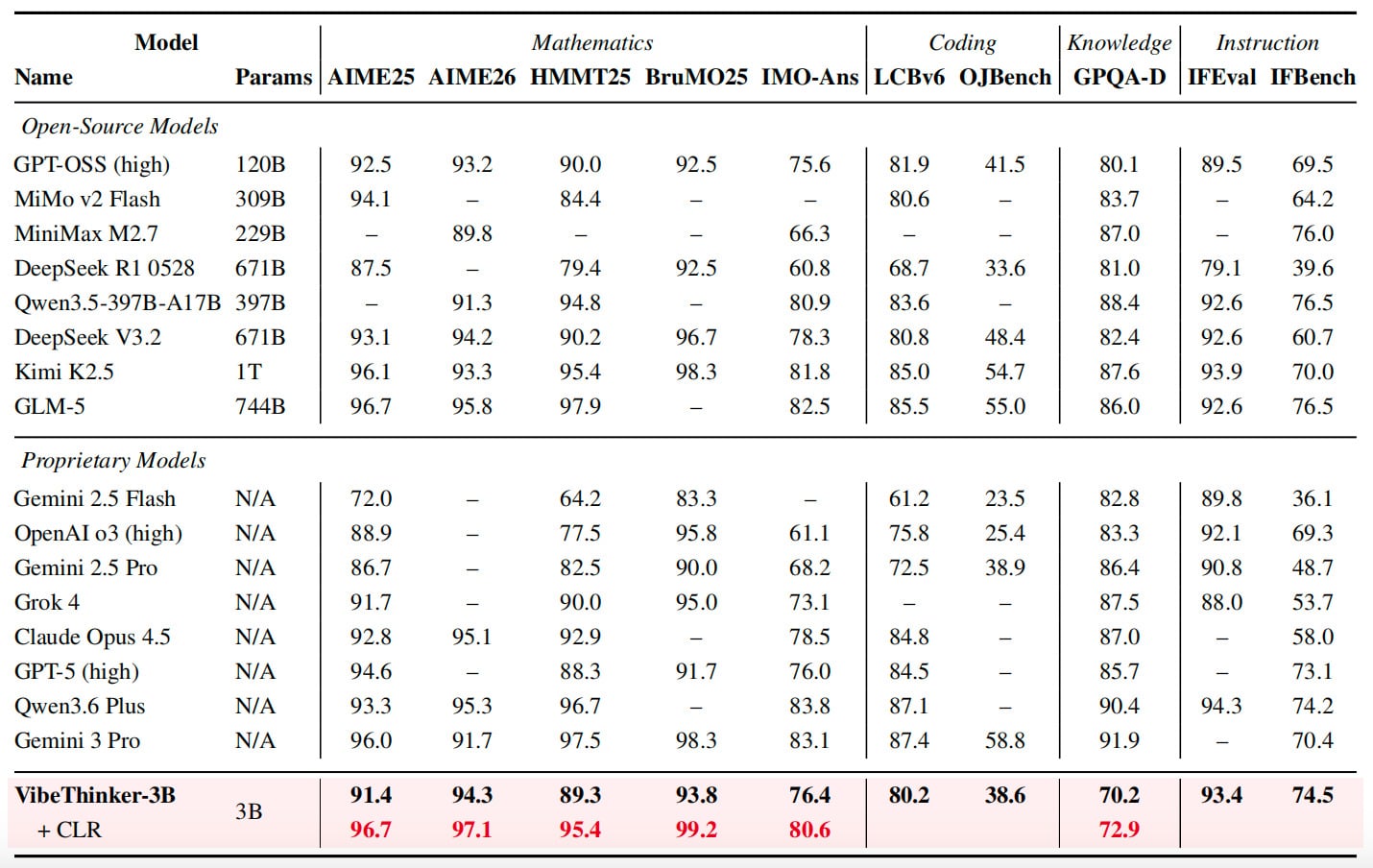
To ensure data integrity, the Sina Weibo team performed strict benchmark decontamination. They filtered for overlapping text to prevent “cheating” on tests. Despite these measures, some users report a gap between benchmark success and practical tool integration. This highlights the ongoing challenge of translating laboratory precision into real-world software engineering utility.
The Situation Room: Socio-Economic Impact
For the Pakistani citizen, this development is a structural breakthrough. High-end AI previously required expensive cloud subscriptions or industrial-grade GPUs. This tiny AI model runs efficiently on a standard consumer laptop. Consequently, Pakistani students and freelance developers can now access frontier-level reasoning tools without the burden of high operational costs. This democratizes innovation across both urban centers and rural areas.
The Situation Room: The Forward Path
This development represents a Momentum Shift. The success of VibeThinker-3B proves that the future of AI is not just about “bigger” but about “smarter.” By reducing post-training costs from $294,000 to just $7,800, the Sina Weibo team has provided a blueprint for localized, sovereign AI development. We expect to see a rise in hybrid systems where small models handle logic and large models provide factual context.
Open-Source Accessibility
In a move that supports global collaboration, the model was released under the MIT License. Within 24 hours, the developer community produced GGUF quantized versions for immediate use. The project has already gained significant traction on Hugging Face and GitHub, signaling a strong demand for open-source, efficient reasoning engines.
- Architecture: Based on Qwen2.5-Coder-3B.
- Cost Efficiency: Post-training cost estimated at only $7,800.
- Portability: Optimized to run on consumer-grade hardware.
- Availability: Weights accessible via Hugging Face and ModelScope.







