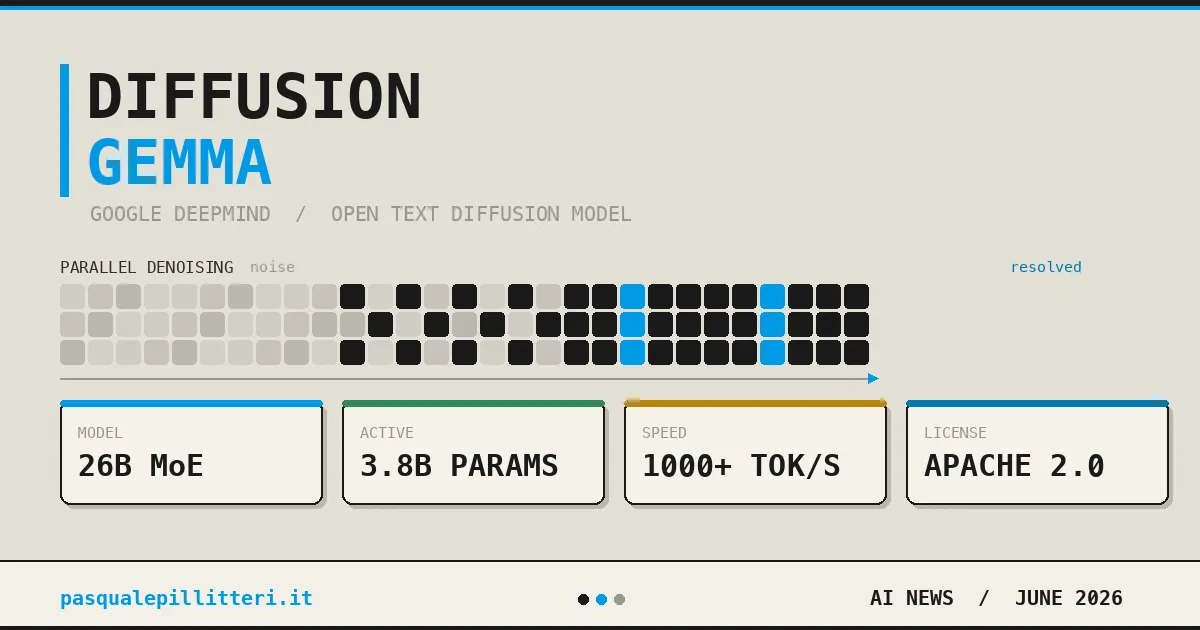
Google recently deployed the DiffusionGemma AI model, an experimental breakthrough that accelerates text generation by shifting from traditional token-by-token processing to a high-speed diffusion approach. This calibrated shift allows the model to produce text 4x faster on standard consumer GPUs. Consequently, developers can now achieve enterprise-grade speeds without relying on massive cloud server farms.
The Architectural Shift: Parallel vs. Sequential Decoding
Traditional large language models generate text sequentially, processing one token at a time from left to right. While effective for cloud-based batching, this method often leaves local GPUs underutilized. In contrast, the DiffusionGemma AI model generates 256 tokens in parallel during each forward pass. This structural innovation allows the system to draft and refine entire blocks of text simultaneously.

By shifting the performance bottleneck from memory bandwidth to raw compute, Google has optimized the model for dedicated hardware. Specifically, the model achieves the following performance metrics:
- NVIDIA H100: Over 1,000 tokens per second.
- NVIDIA GeForce RTX 5090: Over 700 tokens per second.
- Consumer VRAM: Operates efficiently within 18 GB limits when quantized.
Maximizing the DiffusionGemma AI Model on Local Hardware
Google calibrated this model specifically for researchers and developers focused on speed-sensitive workflows. The architecture utilizes bi-directional attention, meaning every token in a block interacts with all others. This is a critical catalyst for non-linear tasks such as code infilling, mathematical graphing, and rapid iterative editing.

Practical Applications and Task Efficiency
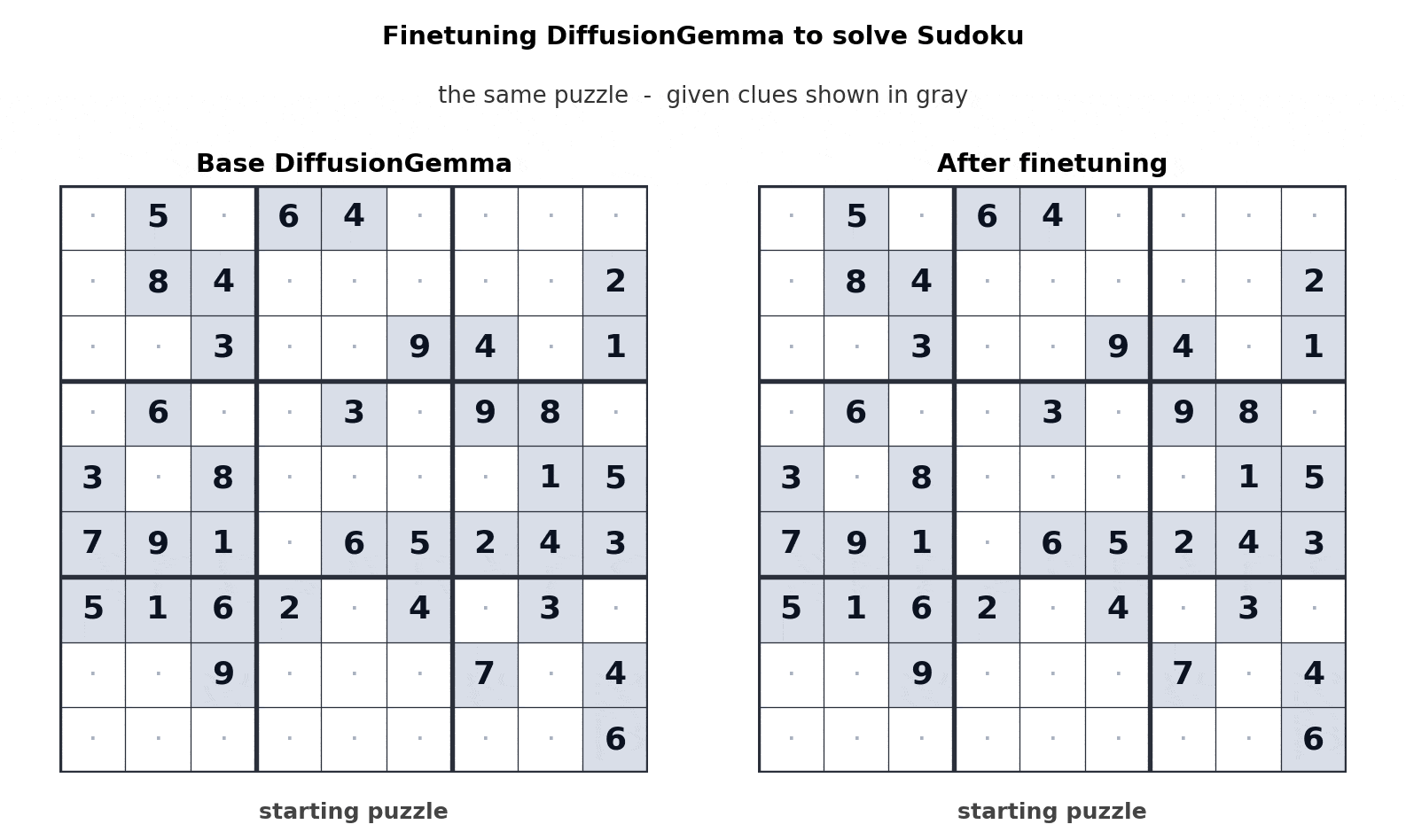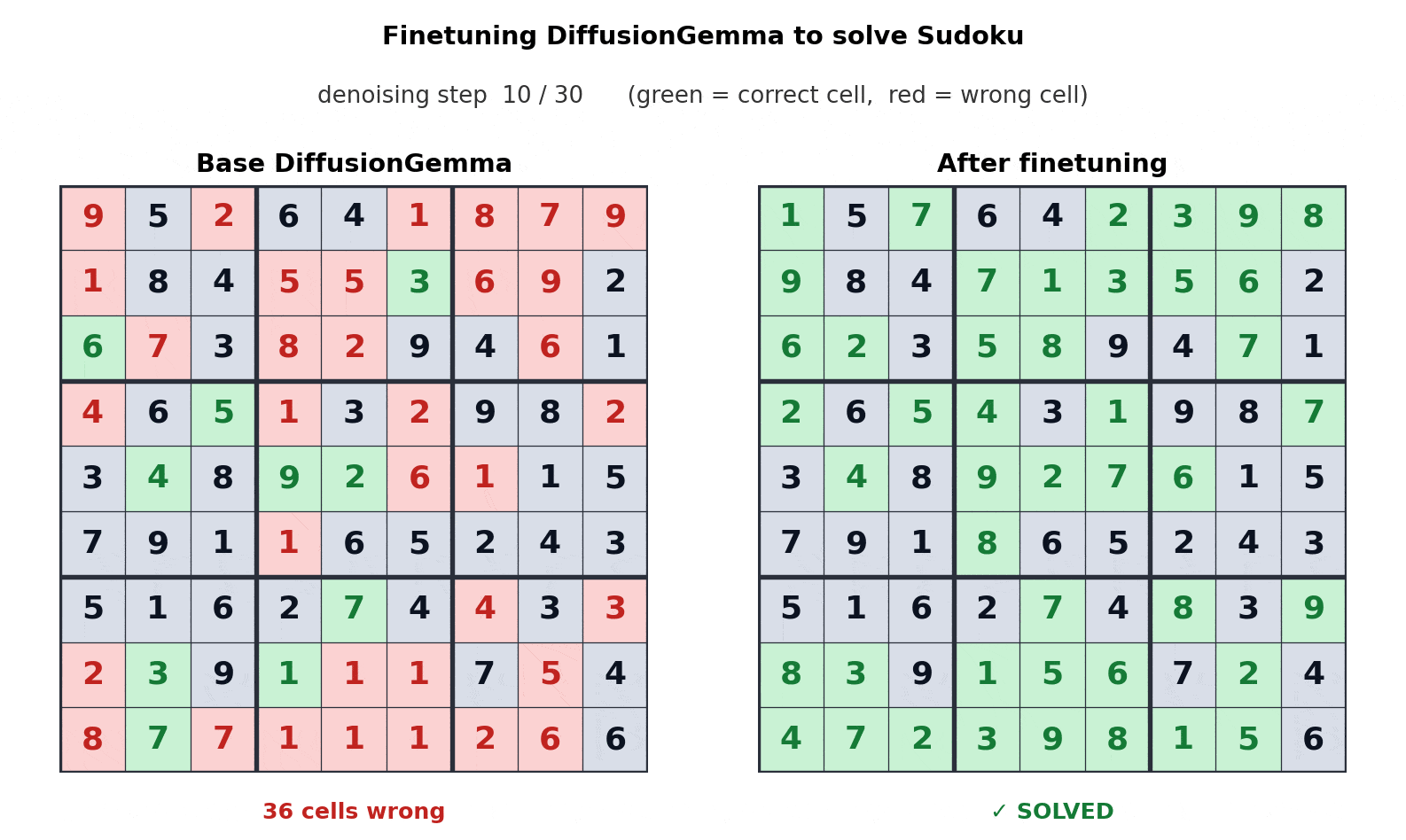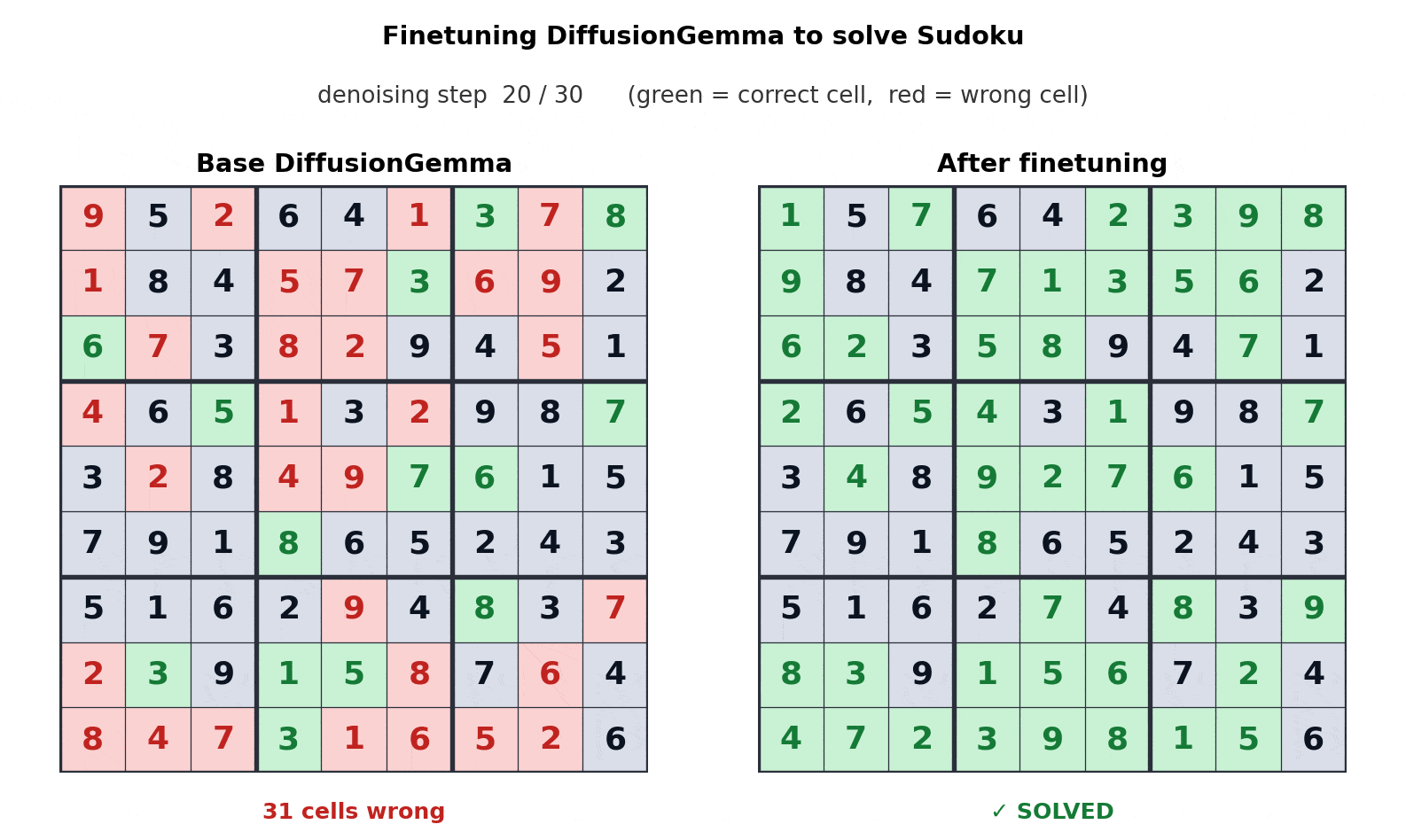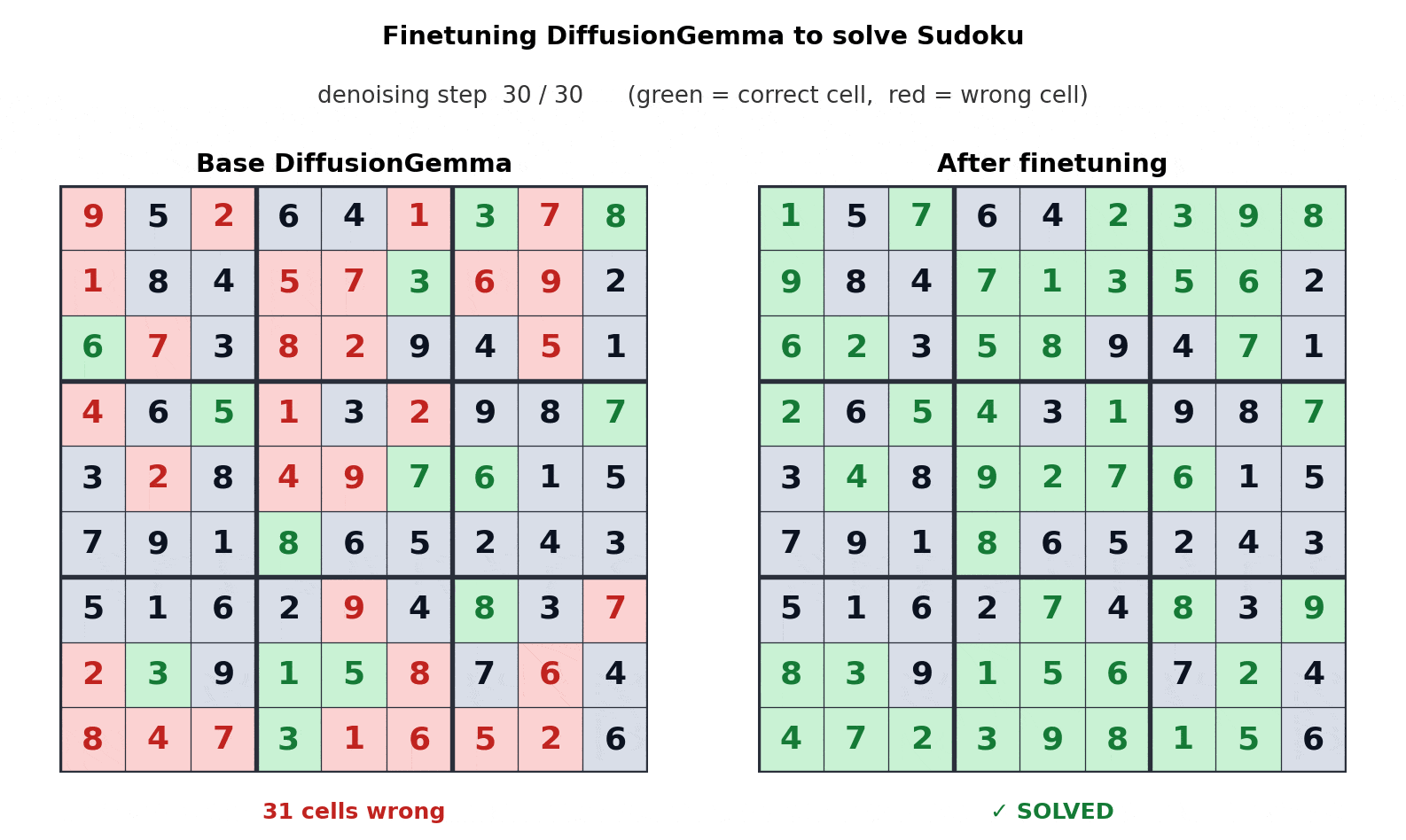
The bi-directional nature of DiffusionGemma solves complex logic puzzles that stump autoregressive models. For example, in Sudoku generation, the model considers the entire grid simultaneously rather than guessing square-by-square. Furthermore, it supports iterative self-correction, refining its own output as it generates to ensure structural integrity in code and markdown.
The Situation Room: Analysis for Pakistan
The Translation: Contextualizing the Tech
Most AI models “talk” like a human, one word at a time. DiffusionGemma “thinks” like a painter, sketching a whole paragraph and then filling in the details in seconds. By moving away from sequential generation, Google has made AI “lighter” for hardware. While it may sacrifice a slight degree of nuance compared to the massive Gemma 4 models, it gains massive utility for real-time applications.
The Socio-Economic Impact: Empowering Local Innovation
For the Pakistani developer community, high cloud costs and varying bandwidth are significant barriers to AI adoption. This development changes the daily life of a local professional by enabling high-speed, local AI processing on standard gaming GPUs like the RTX 4090 or 5090. Consequently, students and startups in Lahore, Karachi, and Islamabad can build complex AI tools without paying expensive monthly subscription fees to international cloud providers.
The Forward Path: Our Expert Opinion
We classify this as a Momentum Shift. While Google labels this as “experimental,” the move toward diffusion-based text models represents a strategic pivot in AI efficiency. This isn’t just about maintenance; it is a catalyst for a future where powerful AI resides on your desk, not just in a distant data center. The Apache 2.0 license further ensures that Pakistani innovators have the structural freedom to modify and build upon this foundation.