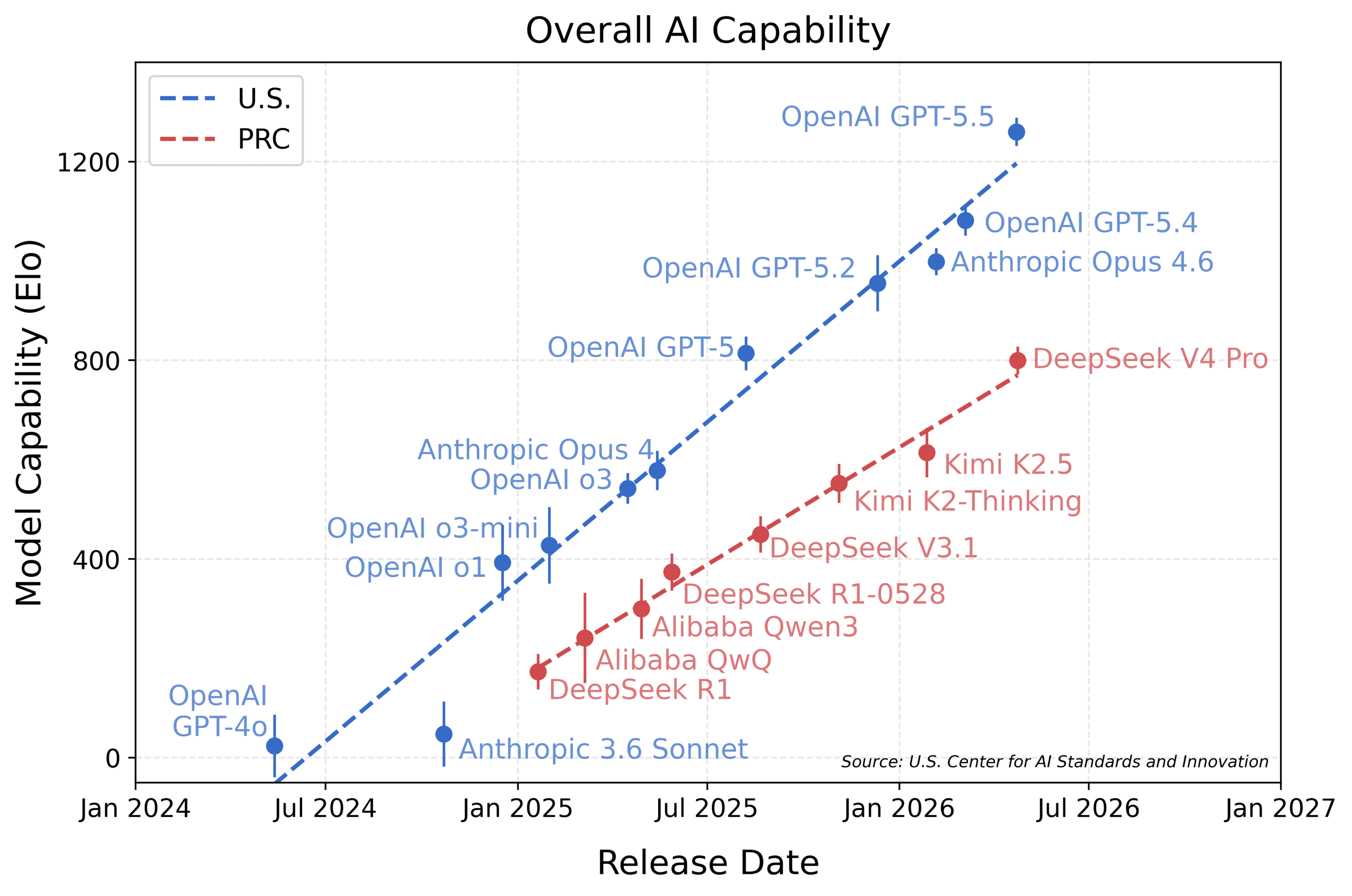
The illusion of competitive parity within the frontier AI landscape has been shattered by a calibrated new assessment tool. Datacurve’s introduction of AI coding benchmarks, specifically the DeepSWE framework, reveals that leading models like GPT-5.5 are significantly ahead of their competitors. While public leaderboards previously suggested a narrow margin between OpenAI, Anthropic, and Google, this new data identifies a massive 16-point performance gap. Consequently, engineering leaders must now re-evaluate the structural integrity of the tools they integrate into their development pipelines.
The Structural Flaw in Current Evaluation
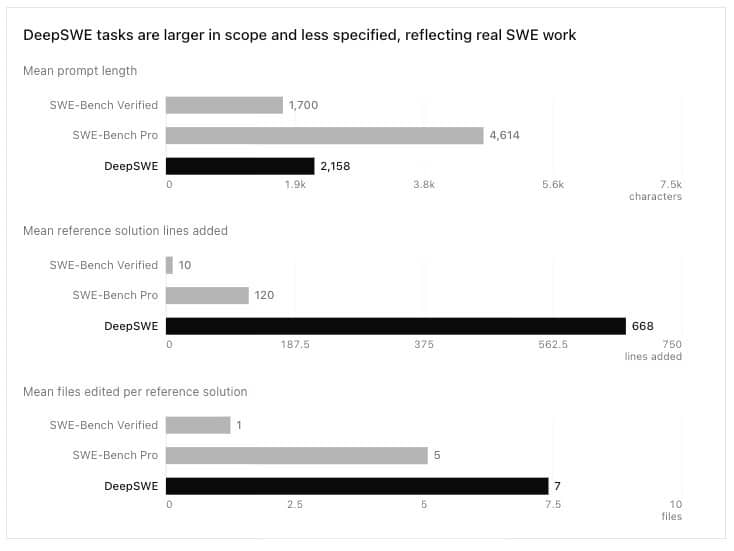
For months, legacy metrics like SWE-Bench Pro suggested that frontier models performed within a tight range. However, this perceived equilibrium was largely a byproduct of benchmark contamination. Because many test tasks originate from public GitHub repositories, the solutions often reside within the model’s training data. This creates a precision error where models appear more capable than they are in novel environments. DeepSWE addresses this by utilizing 113 complex tasks across 91 open-source repositories, ensuring a more rigorous and unique testing environment.

Furthermore, the scale of these tasks has increased dramatically. While traditional AI coding benchmarks average 120 lines of code, DeepSWE reference solutions average 668 lines. This 5.5x increase in complexity forces AI agents to manage larger contexts and more intricate dependencies. By providing shorter prompts with less instruction, the benchmark simulates the realistic, high-pressure experience of professional developers.
Calibrating Verifier Reliability
A critical catalyst for this ranking shift is the improved accuracy of automated graders. Datacurve’s research found that legacy verifiers often penalized valid solutions or accepted incorrect ones. Specifically, SWE-Bench Pro rejected correct code 24% of the time. In contrast, DeepSWE has reduced this error rate to a mere 1.1%. This precision ensures that model progress is measured by actual problem-solving capability rather than the ability to match a specific author’s coding style.
GPT-5.5: Establishing a New Performance Baseline
The results from DeepSWE have recalibrated the industry leaderboard. GPT-5.5 emerged as the clear leader with a 70% success rate, leaving GPT-5.4 and Claude Opus 4.7 trailing at 56% and 54%, respectively. Mid-tier models, which previously appeared competitive, saw their scores collapse under the weight of more complex tasks. For instance, Claude Haiku 4.5 dropped to 0%, suggesting that its previous high marks were likely inflated by easier or contaminated datasets.
Efficiency also remains a strategic differentiator. GPT-5.5 achieved its dominant score with a median cost of $5.80 per trial. While some models were cheaper, they failed to deliver the same structural accuracy. Interestingly, higher computational spending did not consistently correlate with better outcomes, highlighting that architectural precision is more valuable than raw processing power in modern AI coding benchmarks.

The Situation Room Analysis
The Translation: Technical Clarity
Essentially, we are moving from “open-book” testing to “real-world” problem-solving. Most AI models were previously tested on problems they had already seen during training. DeepSWE forces these models to act as true engineering agents. It requires them to write more code with less guidance, exposing which models actually “understand” logic versus those that simply “recall” patterns.
The Socio-Economic Impact: Daily Life in Pakistan
For Pakistan’s growing software export sector, this data is a catalyst for efficiency. Local developers and startups can now make data-driven decisions on which AI agents to invest in. By adopting the most precise models, Pakistani tech firms can reduce debugging time and increase the volume of code delivered to international clients, directly boosting the digital economy’s baseline productivity.
The Forward Path: Momentum Shift
This development represents a significant Momentum Shift. We are witnessing the end of the “parity era” and the beginning of a clear hierarchy in agentic AI. As benchmarks become more rigorous, the gap between truly innovative architectures and derivative models will only widen. For Pakistan to stay competitive, our local tech ecosystem must pivot toward these high-precision tools immediately.